Introduction
Large Language Models (LLMs) have made tremendous strides in recent years, yet the question of how to make machines truly "reason" remains a central challenge. Traditional methods of training AI often rely heavily on supervised fine-tuning, requiring vast datasets of labeled examples. This approach has yielded impressive results in domains like image recognition, language translation, and conversational AI, but its limitations become evident when tackling tasks requiring creativity, adaptability, and reasoning beyond pre-learned patterns.
Enter DeepSeek R1, a groundbreaking large language model that takes a fundamentally different approach: it relies on pure reinforcement learning (RL) to train its reasoning capabilities. Developed as part of the ongoing pursuit of more general AI systems, DeepSeek R1 showcases the immense potential of RL to enable self-improvement without needing massive supervised datasets.
DeepSeek R1 doesn’t just solve problems, it thinks through them. It leverages Chain-of-Thought (CoT) reasoning, a simple yet powerful prompting technique that makes the model articulate its thought process step-by-step. This allows the model to refine its own reasoning, identify errors, and correct them on the fly, making it more accurate over time.
In this post, we’ll explore the insights gained from training AI with pure reinforcement learning, as demonstrated by DeepSeek R1. We’ll break down its key features, innovative training techniques, and why it represents a paradigm shift in AI development. Whether you’re an AI enthusiast or a newcomer curious about the next frontier in machine learning, this is a story of how machines are beginning to learn like humans: through trial, error, and self-reflection.
Who is DeepSeek?

DeepSeek is a Chinese AI company founded by Liang Wenfeng that focuses on developing fundamental AI technology rather than market-ready products. The company is committed to making all its AI models open source, enabling anyone to use and modify them.
Before founding DeepSeek, Wenfeng established High-Flyer, one of China's top four quantitative hedge funds, valued at $8 billion. High-Flyer provides full funding for DeepSeek, which has no plans to seek additional investment.
DeepSeek has launched chat applications for both web and mobile platforms, along with an API platform for developers interested in using their models.
Notably, DeepSeek managed to train V3 at a significantly lower cost of $6 million while using less powerful NVIDIA GPUs due to US export restrictions. They relied on NVIDIA H800 GPUs, which have approximately half the data transfer rate of the H100 (unavailable in China). Despite these limitations, DeepSeek-V3's training required only 2.8 million GPU hours, compared to Llama 3 405B's estimated 30.8 million GPU hours. These hardware restrictions appear to have driven DeepSeek to optimize their model training and inference processes.
DeepSeek V2 and V3
To understand the significance of the R1 model, let's examine its predecessors.
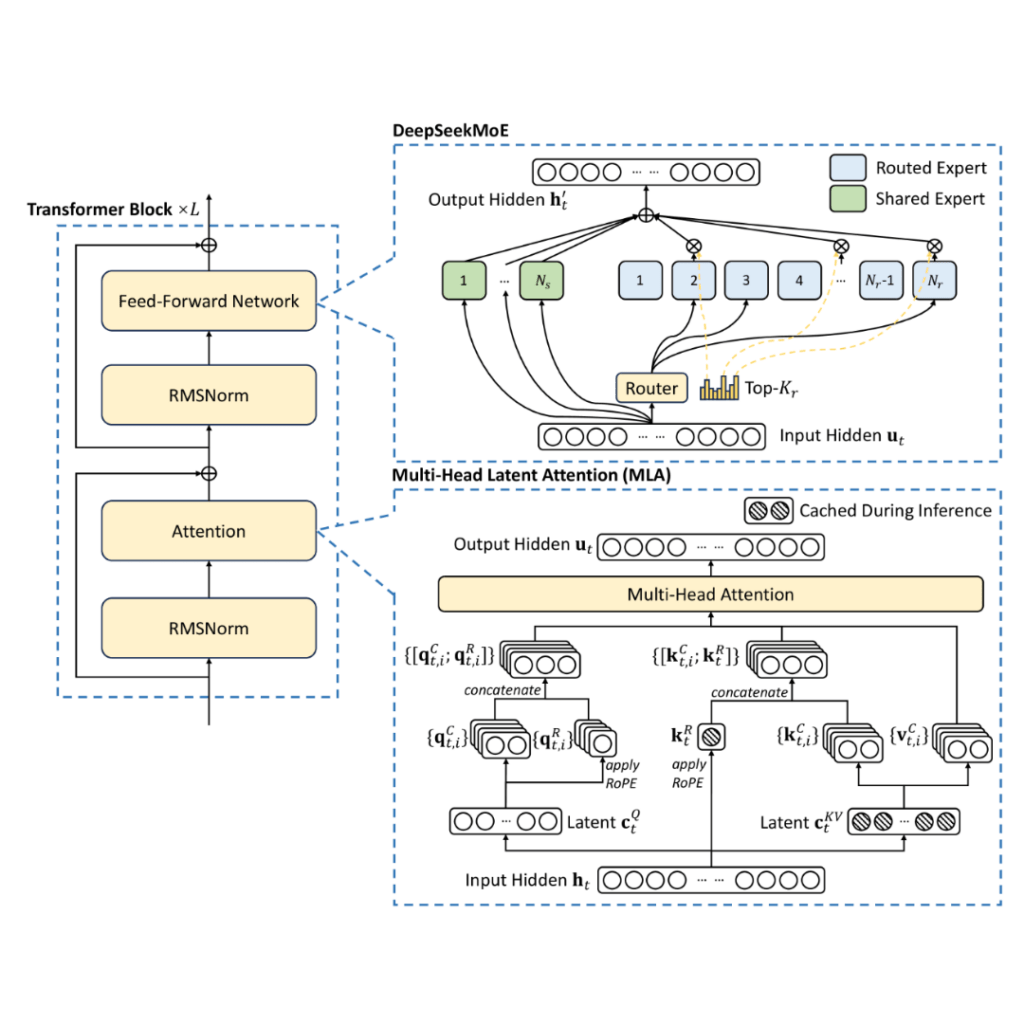
DeepSeek-V2 introduced two major innovations: DeepSeekMoE (Mixture-of-Experts) and DeepSeekMLA (Multi-head Latent Attention).
The Mixture-of-Experts technique, first introduced by Robert A. Jacobs and Geoffrey Hinton in their 1991 paper "Adaptive Mixtures of Local Experts" , uses multiple expert networks to divide complex problems into manageable regions. This approach enhances both accuracy and efficiency in machine learning. While ChatGPT 3.5 activates its entire model during training and inference, MoE divides the model into specialized experts. When processing a query, only the relevant experts activate, reducing power consumption and increasing speed. GPT-4 implements this MoE architecture with an estimated 16 experts, each containing approximately 110 billion parameters.
DeepSeekMoE in V2 enhances the traditional Mixture-of-Experts by:
- Specialized vs. Shared Experts: Using both specialized experts for specific tasks and shared experts for general knowledge.
- Efficient Training: Improving load-balancing and routing during training, which reduces communication overhead and makes training more efficient. This contrasts with traditional MoE, which sacrifices training efficiency for efficient inference.
DeepSeekMLA (multi-head latent attention) tackles a major inference bottleneck: memory consumption. It reduces the memory needed for storing the context window by compressing the key-value pairs associated with each token. This allows for larger context windows and more efficient inference overall.
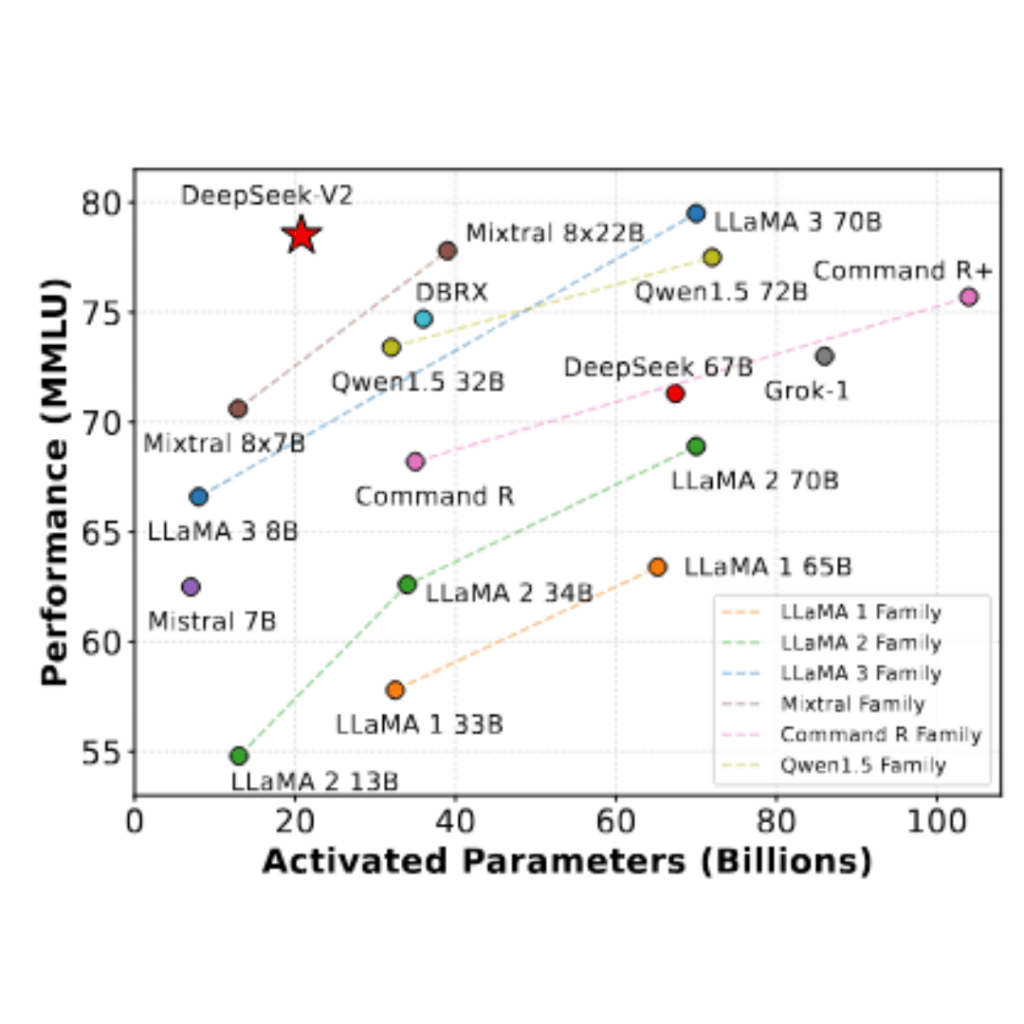
The results are impressive, as shown in the DeepSeek-V2 paper:

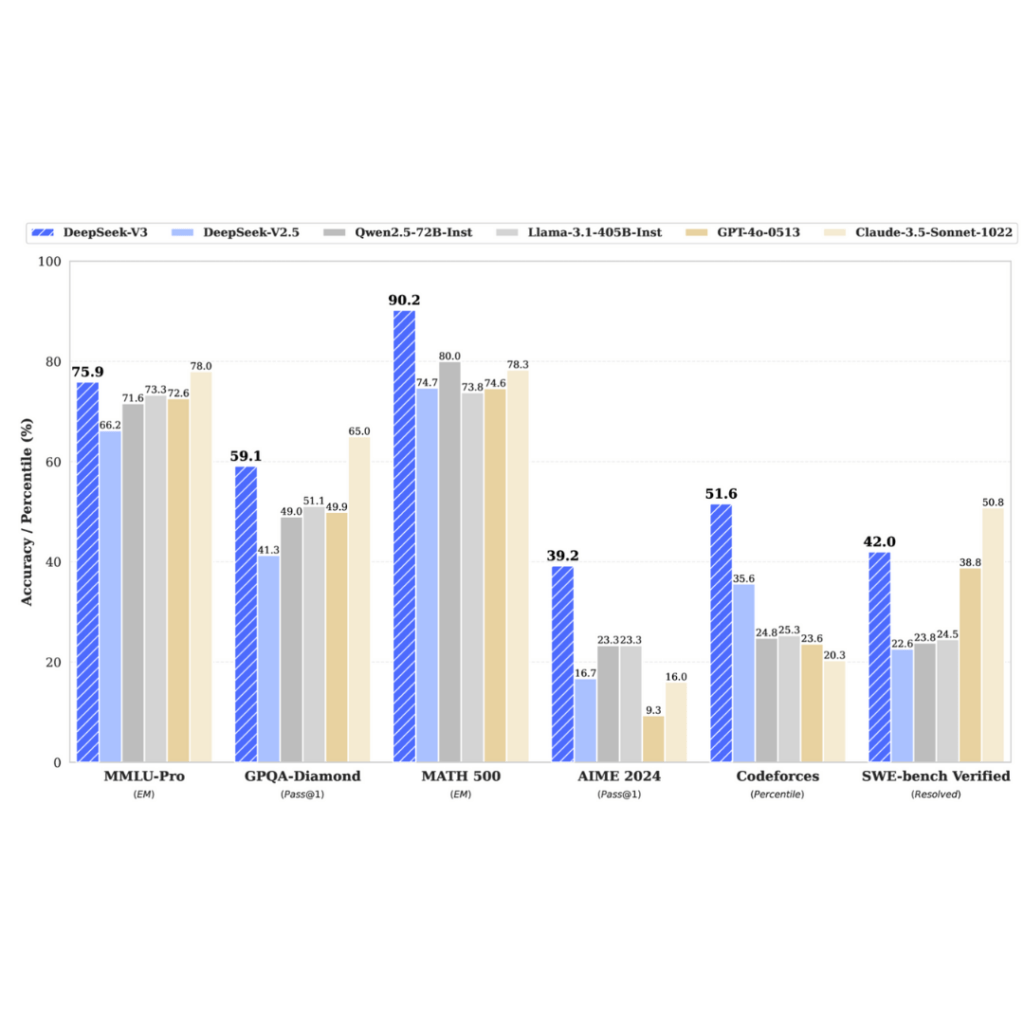
V3 enhanced DeepSeek's previous innovations by improving load balancing and implementing multi-token prediction during training. These advancements led to remarkable cost savings, with DeepSeek spending just $5.576 million to train V3. This demonstrated that large language models could be trained efficiently and economically.
DeepSeek-V3 architecture:
You can find more details about DeepSeek’s V3 architecture here.
What Makes DeepSeek R1 Unique?
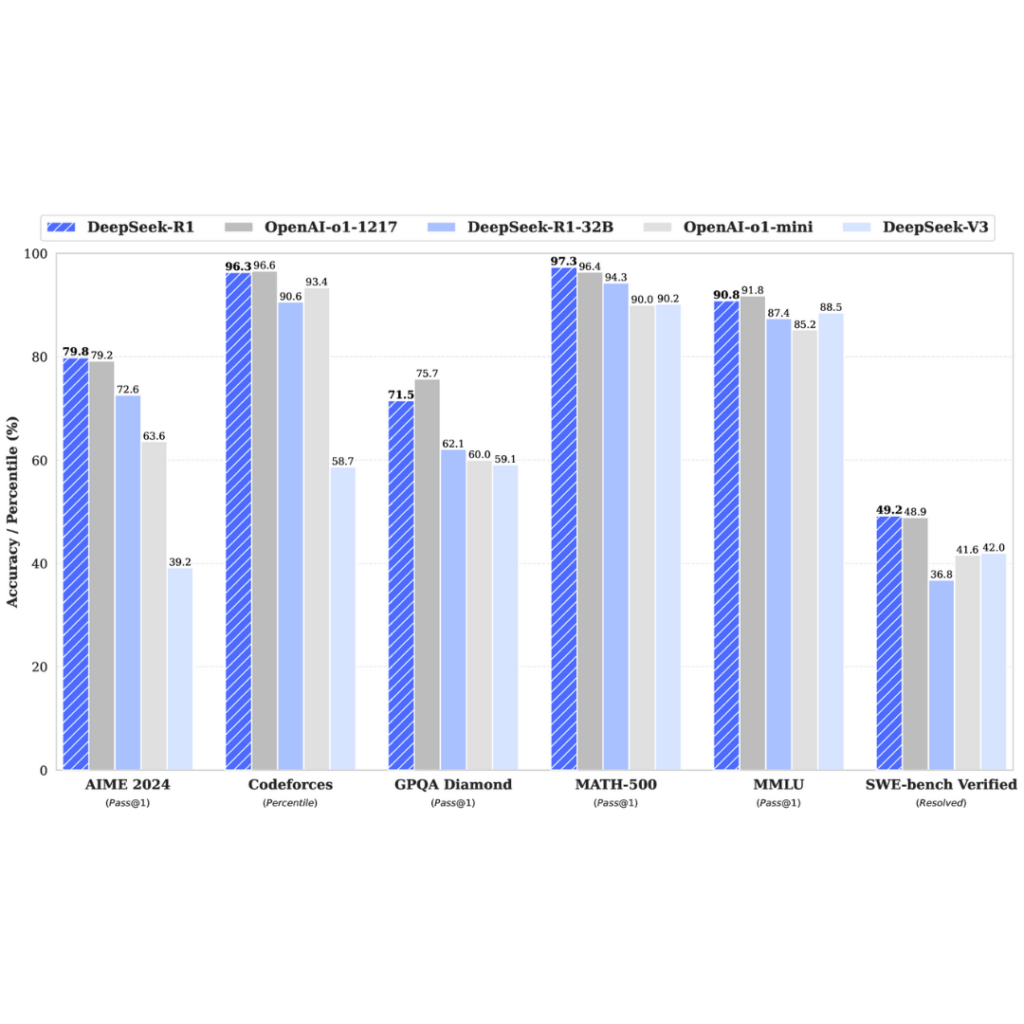
DeepSeek R1 redefines the rules by pioneering a training process centered around pure reinforcement learning (RL), bypassing the traditional reliance on supervised fine-tuning. This approach sets it apart as a model capable of teaching itself complex reasoning capabilities. Below are the standout features that make DeepSeek R1 a trailblazer in AI research.
Pure Reinforcement Learning: A New Approach to Model Training
Most AI systems today are built using vast datasets annotated by humans, where the model is trained to predict the correct output based on labeled input. In contrast, DeepSeek R1-Zero, the initial version of the model, is trained entirely through reinforcement learning. This means that the model starts with no prior knowledge and gradually improves itself by interacting with its training environment and optimizing its policy—the set of rules it uses to make decisions.
- Learning Without Labels: Unlike traditional methods, which require expensive, annotated datasets, DeepSeek R1-Zero learns autonomously by maximizing a reward signal. It explores different ways to solve problems, much like how a child experiments with walking until they master the skill.
- Self-Evolution: The model continuously refines its behavior through trial and error, achieving higher performance with each iteration of training. Over time, it develops increasingly sophisticated strategies for reasoning and problem-solving.
Chain-of-Thought (CoT) Reasoning: Teaching AI to Think Out Loud
One of the most innovative aspects of DeepSeek R1 is its use of Chain-of-Thought reasoning, a straightforward yet powerful prompting technique. Rather than asking for immediate answers, CoT guides the model to break problems into smaller, logical steps while explaining its reasoning throughout the process.
- Enhanced Error Detection: Through this transparent reasoning process, DeepSeek R1 can pinpoint flaws in its logic and self-correct as it learns. During a math problem, for instance, the model actively monitors its progress, pausing to say, "Wait, let me check this again," before finalizing its answer.
- Human-Like Reasoning: This approach mirrors natural human problem-solving, where we think through solutions step by step, making it easier to identify and correct logical errors along the way.
Emergent Behaviors and Self-Reflection
During training, DeepSeek R1 develops remarkable behaviors that emerge naturally, without explicit programming. These behaviors include:
- Self-Reflection: The model independently reviews and reconsiders its steps when facing inconsistencies. Like a human's "aha moment," it can recognize mistakes and retrace its reasoning to find the right solution.
- Exploratory Learning: Rather than simply memorizing patterns, the model actively tests different approaches to problems, finding the most effective solutions. This leads to better performance on new, unfamiliar tasks.
Reward Systems: Driving Reinforcement Learning
DeepSeek R1's training revolves around a sophisticated reward system that shapes its reasoning and decision-making abilities.
- Accuracy Rewards:
- The model earns rewards by matching its predictions to ground truth answers. In tasks with clear right or wrong answers, like mathematics, this creates a precise feedback loop.
- The system uses rule-based verification, testing code against specific cases and validating mathematical solutions against established formulas.
- Format Rewards:
- The model receives additional rewards for clear, well-structured responses. It learns to express its reasoning process using specific tags like
<think>and<answer>. - This structured approach enhances clarity and facilitates smoother interaction between humans and the model.
- The model receives additional rewards for clear, well-structured responses. It learns to express its reasoning process using specific tags like
Distillation: Making AI Accessible
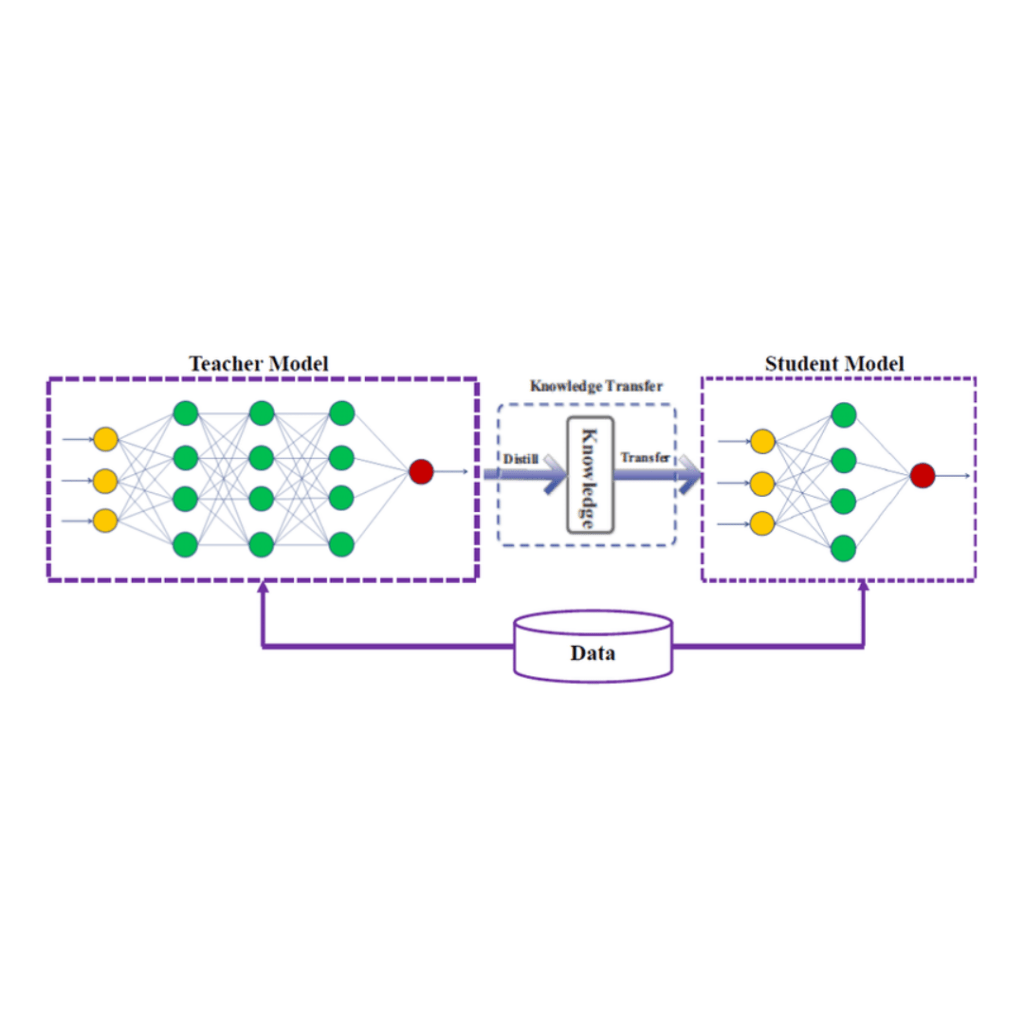
While DeepSeek R1 marks a breakthrough in AI reasoning capabilities, its full-scale model demands extensive computational resources. To democratize these advanced reasoning abilities, DeepSeek uses a process called distillation. This section explores how distillation enables smaller models to harness the power of their larger counterparts.
Model distillation works by transferring knowledge from a large "teacher" model to a smaller "student" model. This creates compact, efficient models that maintain comparable performance while using far fewer resources.
How It Works:
- The teacher model (e.g., DeepSeek R1 671B) solves tasks and demonstrates reasoning through them, showcasing detailed Chain-of-Thought reasoning.
- The student model then trains on these outputs, learning to replicate the reasoning process and generate similar high-quality answers—effectively inheriting the larger model's knowledge.
Distilled Versions of DeepSeek R1
DeepSeek has created several streamlined versions of the model, each tailored for specific uses and resource limitations:
These distilled models come in various sizes—7B, 14B, 32B, and 70B parameters—making them far more accessible than the 671B-parameter full-scale DeepSeek R1.
Though smaller, these models excel against many open-source alternatives. For example:
- DeepSeek-R1-Distill-Qwen-7B scores 55.5% on AIME 2024, surpassing larger models like QwQ-32B.
- DeepSeek-R1-Distill-Qwen-32B achieves a 94.3% pass@1 score on MATH-500 and a 72.6% pass@1 score on AIME 2024.
Conclusions
DeepSeek began as Liang Wenfeng's side project to build an AI system for investment optimization. It later evolved into a company dedicated to innovating large language model training and inference.
U.S. sanctions on chip exports have restricted DeepSeek to using lower-performing NVIDIA H800 GPUs. This limitation spurred the company to develop more efficient training methods, leading to improvements in the Mixture-of-Experts approach and the groundbreaking Multi-head Latent Attention mechanism. Their innovations culminated in a pure reinforcement learning training method that—without human feedback—enables the model to simulate human thinking, learn from mistakes, and optimize solutions through reward functions. Another significant breakthrough is their distillation technique, where the 671B-parameter R1 model acts as a teacher, generating training examples for smaller models—a prime example of AI teaching AI.
These innovations offer valuable insights that other open-source models, like Meta's Llama, could adopt to enhance their capabilities. This advancement in open-source LLMs poses a significant challenge to closed-source models like OpenAI's GPT or Google's Gemini, who will need breakthrough innovations to maintain their edge, despite their vast resources.
References
Nvidia tweaks flagship H100 chip for export to China as H800, Reuters, https://www.reuters.com/technology/nvidia-tweaks-flagship-h100-chip-export-china-h800-2023-03-21/
Adaptive Mixtures of Local Experts, R. Jacobs, Michael I. Jordan, S. Nowlan, Geoffrey E. Hinton, https://www.semanticscholar.org/paper/Adaptive-Mixtures-of-Local-Experts-Jacobs-Jordan/c8d90974c3f3b40fa05e322df2905fc16204aa56
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model, DeepSeek-AI, Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, https://arxiv.org/abs/2405.04434
DeepSeek-V3 Technical Report, DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, https://arxiv.org/abs/2412.19437
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, https://arxiv.org/abs/2501.12948
What is Chain Of Thought Prompting & How Does It Work?, Ajay Rathod, https://aiperceiver.com/everything-you-need-to-know-about-chain-of-thought-prompting/
Compact CNN Models for On-device Ocular-based User Recognition in Mobile Devices - Scientific Figure on ResearchGate. Available from: https://www.researchgate.net/figure/Fig-2-Generic-architecture-of-knowledge-distillation-using-a-teacher-student-model_fig2_355180688