Introduction
In the fast-paced world of AI, companies need to leverage every business opportunity they have and understand how to enhance their capabilities by faster processing and optimizing the input.
In this context, one of our customers approached us with a common challenge in the space. They needed an automated solution to extract structured information from a variety of PDF documents, each tailored to different institutions. The extracted data had to follow a precise hierarchical format while eliminating unnecessary details. Additionally, the documents contained both text and images, with some text appearing vertically or embedded in images.
To solve this challenge, we leveraged Google Cloud Platform (GCP), utilizing Document AI for Optical Character Recognition (OCR), and Vertex AI to structure the extracted data into a clean, tree-like format. This article explores our approach and the key learnings from the project.
The Challenge
Our client needed to process a large set of unstructured PDF documents containing institution objectives and the means to achieve them. We had to parse and extract this information building a structured database.
The main hurdles we faced while approaching this task included:
- Diverse document formats: Some PDFs contained only images, while others had a mix of text and visuals.
- Varying text orientations: Text appeared both horizontally and vertically, requiring robust OCR capabilities.
- Need for exact hierarchical extraction: The data contained goal-oriented structures that had to be preserved in a tree format.
- Institution-specific information: Each document was associated with a different institution, and this had to be incorporated into the extracted structure.
- Strict content preservation: The AI had to preserve the extracted content exactly. The output had to be an exact copy of the text present in the document, without interpretation or modification.
Our Solution
We developed a web application that streamlines the extraction of structured data from PDFs. The stack includes:
- Frontend: React
- Backend: Node.js with Express
- Authentication: Auth0
- AI Processing: Google Cloud’s Document AI and Vertex AI
- Database: PostgreSQL
- Caching: Redis
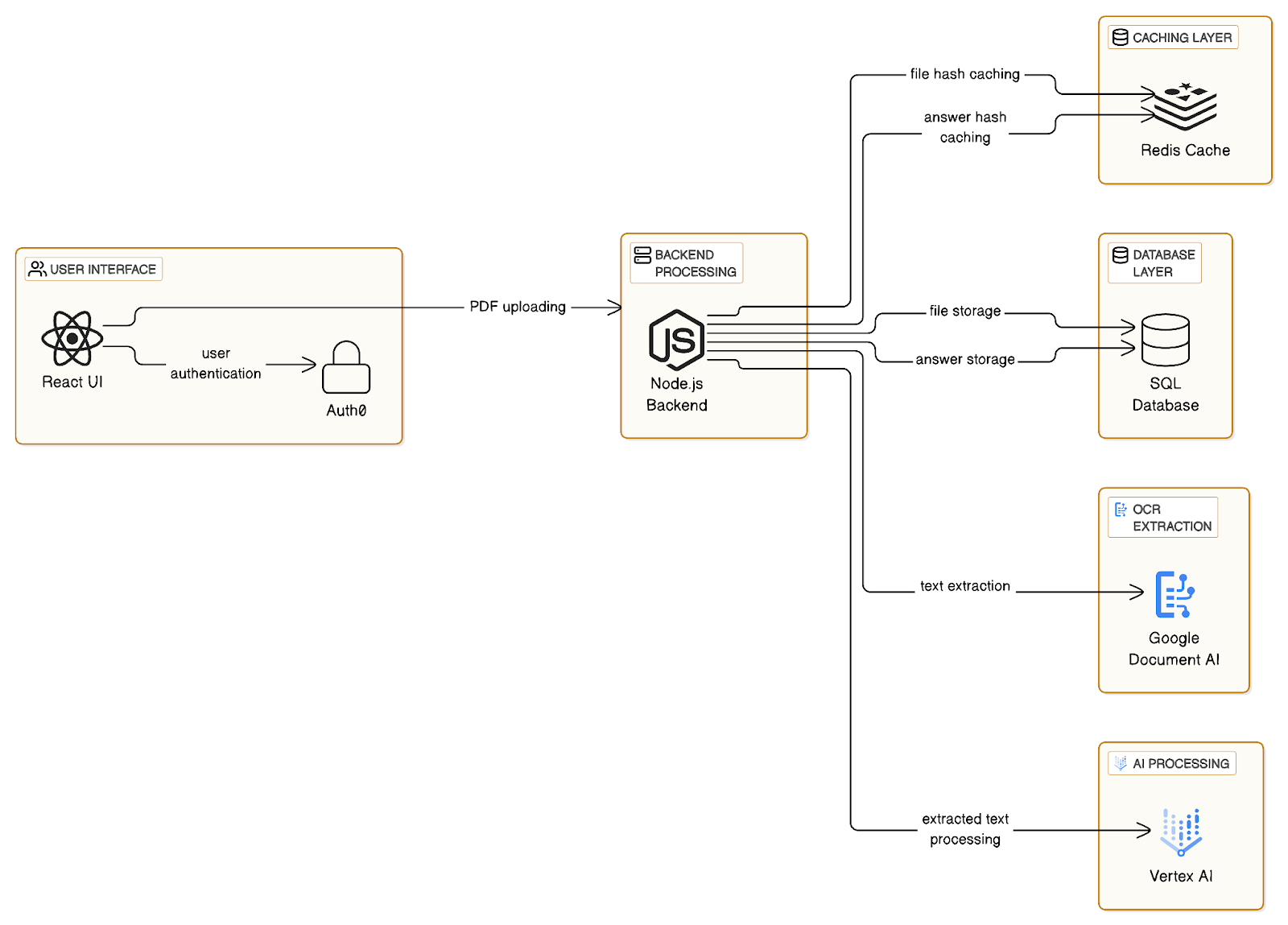
Workflow
- Users upload a PDF document(max 15 pages per file) via a web interface.
- The document is processed using Google Document AI for text and OCR extraction.
- Users review and verify the extracted text before further processing
- The text is then further processed using Vertex AI. It transforms the raw text into a hierarchical tree structure, preserving key objectives and relationships.
- The structured data is displayed for final review and then stored in a database if approved
OCR Extraction with Google Document AI
Since many PDFs contained images with embedded text, we utilized Google Document AI’s OCR capabilities to extract textual content. This ensured that we captured both traditional and vertically aligned text, as well as text embedded in images.
Structuring the Data Using Vertex AI
After OCR extraction, the raw text was processed using Vertex AI. The prompt played a crucial role in ensuring the correct hierarchy was obtained. We instructed the AI to:
- Identify and prioritize specific keywords related to goals and objectives.
- Structure the extracted data into a tree format where:
- The institution name was the first-level node.
- Each goal started with a single star (*).
- Each sub-objective nested under a goal was prefixed with two stars (**), and so on.
- The hierarchy continued infinitely, with each deeper level receiving an additional star.
Example output structure:

By formatting the output this way, we could easily parse and store the data in a structured format.
Filtering Out Useless Details
To eliminate unnecessary details, we provided explicit instructions within the AI prompt. This ensured that only relevant information was extracted, improving the accuracy and relevance of the final output.
The AI Prompt
To achieve the best possible extraction results, we fine-tuned our prompt as follows:
1. Task Definition:
Extract the name of the institution and a tree structure based on the content. Extract the details about each category as separate levels.
2. System Instructions:
You are a document analyst responsible for extracting structured information with absolute accuracy. The content represents a strategic plan hierarchy. You must preserve the original wording exactly as it appears in the document.
3. Hierarchy Formatting Rules:
Do not include any empty lines.
Each level must begin with exactly one more * symbol than the previous level, ensuring a structured indentation format.
Each level should start on a fresh line.
Do not include headings.
No other formatting should be applied to the result.
Do not add any other notes or explanations.
4. Keyword Prioritization:
Focus on extracting content related to the following terms: Objectives, Imperatives, Initiatives, Goals, Priorities, Targets, Milestones, Themes, Directives, Focus Areas, Programs, Projects, Actions, Tasks.
Exclude content associated with: Mission, Vision, Values, Guiding Principles, North Star, Roadmap.
This refinement allowed us to obtain highly structured, relevant information without unnecessary noise.
Key Challenges and How We Overcame Them
Ensuring Hierarchical Accuracy
One major concern was maintaining the integrity of the extracted tree structure. By using a consistent star-based notation system and testing various prompt refinements, we achieved reliable results.
Extracting Institution Names
Some PDFs did not explicitly mention the institution’s name in a clear format. We applied rule-based logic combined with AI-assisted entity recognition to accurately extract and position institution names in the hierarchy.
Plans for Enhancing Future Versions
To further improve our solution, we can think about the following enhancements
Enhancing the AI prompt
We can further refine our prompt engineering. The initial prompt is good enough for our use case but can be further improved. We can send more precise and more concise commands. An example of how an improve prompt can be the following:
1. Task Definition:
Extract structured hierarchical information from the document with absolute accuracy. Identify the institution name and organize relevant details into a tree format using a predefined star-based indentation system.
2. System Instructions:
You are a document analyst responsible for extracting structured information with strict accuracy.
Preserve the original wording exactly as it appears in the document—no rewording or summarization.
Do not include additional notes, explanations, or formatting beyond what is specified
3. Hierarchy Formatting Rules:
Place the institution name at the top level of the hierarchy.
Each goal should begin with a single *.
Each sub-goal should start with **, sub-sub-goals with ***, and so on.
Maintain strict indentation consistency—no empty lines or additional formatting.
4. Keyword Prioritization:
Extract content related to the following categories: Objectives, Imperatives, Initiatives, Goals, Priorities, Targets, Milestones, Themes, Directives, Focus Areas, Programs, Projects, Actions, Tasks.
Exclude any information related to: Mission, Vision, Values, Guiding Principles, North Star, Roadmap.
Reinforcement Learning from Human Feedback (RLHF)
We aim to enhance accuracy by allowing users to provide corrections to the extracted data, which will be fed back into the AI model to refine its performance over time.
Comparison with Other Cloud Solutions
While we used Google Document AI and Vertex AI, alternative solutions exist.
1. OCR Alternatives
- AWS Textract: Provides OCR and structured data extraction but may require additional customization for hierarchical extraction.
- Azure Form Recognizer: Offers OCR and key-value extraction, but its ability to process nested hierarchies requires further evaluation.
2. AI based data structuring:
- Amazon Bedrock: Supports foundation models but lacks a specialized structure extraction framework.
- Azure OpenAI: Allows AI-assisted processing, but similar to Vertex AI, requires precise prompt engineering.
Choosing the right platform depends on the specific requirements, document complexity, and integration needs.
Conclusion
By leveraging Google Cloud’s AI tools, we successfully built an automated pipeline that extracts structured, hierarchical data from complex PDFs. This solution not only streamlined our customer’s workflow but also set the foundation for future AI-driven document processing improvements.
As AI technology evolves, we look forward to further fine-tuning our approach with reinforcement learning, enhancing our ability to deliver precise and scalable document intelligence solutions.